Stable Diffusion 2.0 发布,加强成人内容过滤
发表时间:2025-03-23 17:55:47作者:小静人气:更新时间:2026-04-09 18:07:05
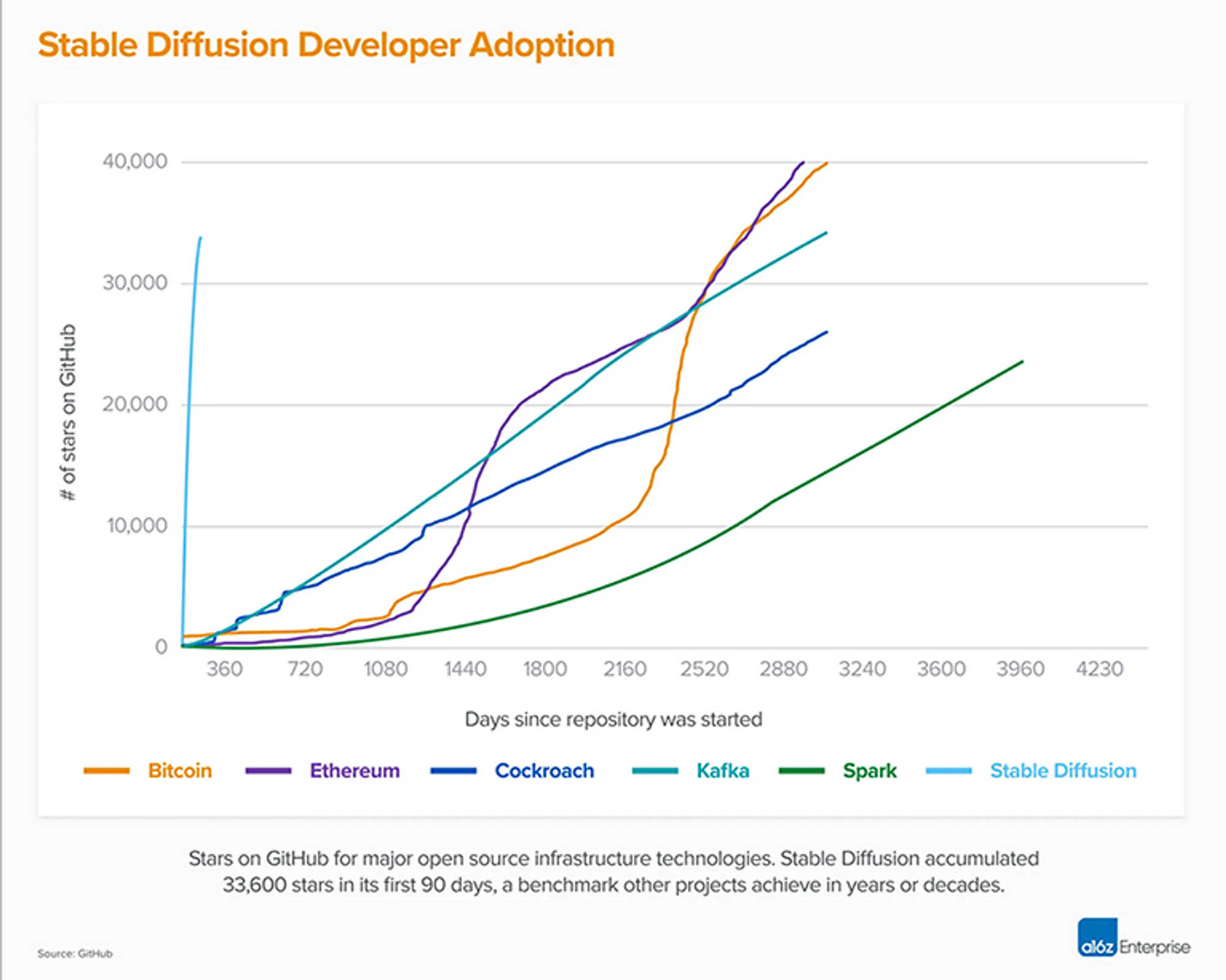
由 CompVis 领导的 Stable Diffusion V1 改变了开源人工智能模型的性质,并在全球范围内催生了数百个其他模型和创新。Stable Diffusion 如今也是所有软件中最快攀升至 Github 10K Stars 的软件之一,在不到两个月的时间里,它的 Stars 飙升至 33K。
Stable Diffusion 2.0 与最初的 V1 版本相比,提供了许多重大的改进和功能。
新的 Text-to-Image(文本转图像)的 Diffusion 模型
Stable Diffusion 2.0 版本包括使用全新的文本编码器(OpenCLIP)训练的文本转图像模型,该模型由 LAION 在 Stability AI 的支持下开发,与早期的 V1 版本相比,大大改善了生成图像的质量。该版本中的文本转图像模型可以生成默认分辨率为 512x512 像素和 768x768 像素的图像。
这些模型是在 Stability AI 的 DeepFloyd 团队创建的 LAION-5B 数据集的子集上训练的,然后使用 LAION 的 NSFW 过滤器进一步过滤以去除成人内容。

超分辨率 Upscaler Diffusion 模型
Stable Diffusion 2.0 还包括一个 Upscaler Diffusion 模型,可以将图像的分辨率提高 4 倍。下面是该模型将一个低分辨率的图像(128x128)提升为高分辨率的图像(512x512)的例子。结合文本转图像模型,Stable Diffusion 2.0 现在可以生成分辨率为 2048x2048 甚至更高分辨率的图像。

Depth-to-Image(深度到图像)Diffusion 模型
新的深度引导的 stable diffusion 模型,称为 depth2img,它扩展了之前 V1 的图像转图像功能,为创造性的应用提供了全新的可能性。depth2img 推断输入图像的深度(使用现有模型),然后使用文本和深度信息生成新的图像。

深度转图像可以提供各种新的创造性的应用,提供与原始图像完全不同的变换,但仍然保留该图像的一致性和深度信息。
更新的 Inpainting Diffusion 模型
新版本还包括一个新的文本指导的绘画模型,在新的 Stable Diffusion 2.0 基础文本转图像上进行了微调,这使得智能地、快速地切换出图像的一部分变得更加容易。

Stability AI 将在未来几天把这些模型发布到 API 平台(platform.stability.ai)和 DreamStudio 上。
相关推荐
相关下载












热门阅览
最新排行
- 1微软尝试模式转变:Win10不仅是软件还是服务
- 2盘点九大新奇又实用的高科技产品:刷脸支付
- 3鲍尔默发布辞呈 立即辞去微软董事发力NBA
- 4海兰GD40CUIF显示器怎么样 海兰GD40CUIF详细评测
- 5微信可以绑定几张银行卡?微信可以绑定银行卡数量介绍
- 6redmipad回收站在哪? redmi pad平板恢复被删除相册的技巧
- 7Stable Diffusion 2.0 发布,加强成人内容过滤
- 8阿里巴巴 Arthas 3.5.0 版本发布,支持反编译打印行号和统一鉴权
- 9谷歌正式推出 Android 11
- 10压线考生志愿如何填 高考志愿填报技巧
- 11WIN10系统怎么调整分区大小 WIN10调整分区大小方法
- 12微信:安卓最新版支持修改微信号 一年可修改一次
网友评论